
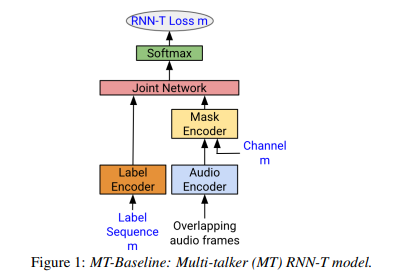
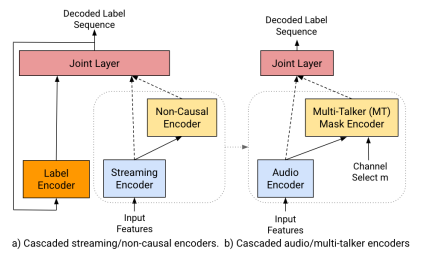
This paper presents a method for improving automatic speech recognition (ASR) performance on speech containing overlapping utterances from more than one speaker. The authors propose a multi-talker ASR (MT-ASR) model that combines a well-trained foundation model with a multi-talker mask model in a cascaded RNN-T encoder configuration. The model is designed to improve word error rate (WER) on overlapping speech utterances while minimizing impact on the performance of the foundation model on non-overlapping utterances. The paper also introduces a mechanism for detecting overlapping speech using a frame-based multi-talker speech activity detector (MT-SAD).
Publication date: June 28, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2306.16398.pdf