

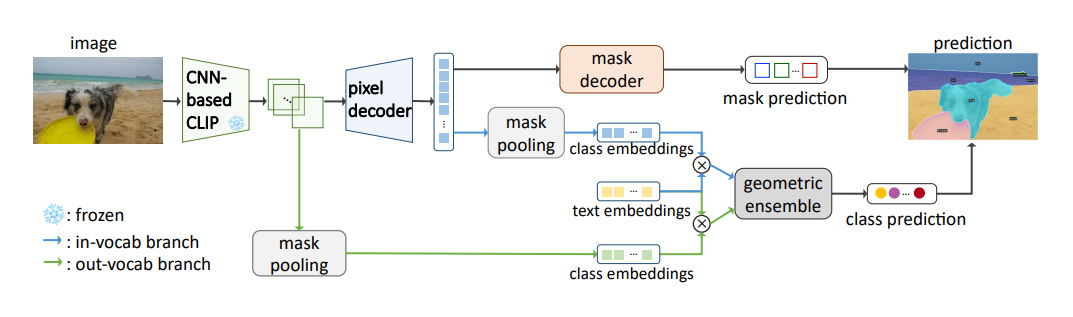
Open-vocabulary segmentation is a pivotal advancement in computer vision, allowing for the segmentation and recognition of objects across a vast set of categories. Traditional methods often employ a two-stage framework involving mask generation and subsequent recognition, which is inefficient as it extracts features from raw images multiple times. This research presents a novel approach that condenses this process into a single stage using a Frozen Convolutional CLIP backbone, termed FC-CLIP. This model not only simplifies the existing process but also produces a more favorable accuracy-cost balance. The novel system outperforms its predecessors in multiple benchmarks, proving its efficiency, effectiveness, and speed.
Publication date: 4 Aug 2023
Project Page: https://github.com/bytedance/fc-clip
Paper: https://arxiv.org/pdf/2308.02487.pdf