
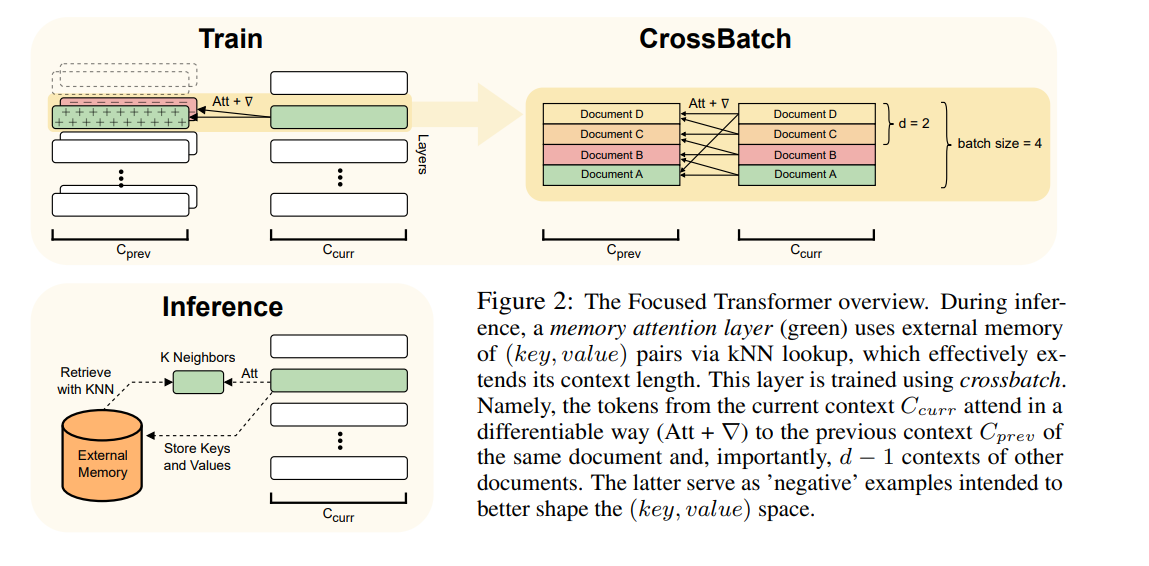
The Focused Transformer (FOT) is a new approach designed to tackle the challenge of scaling the context length in language models. Large language models have the capability to incorporate new information in a contextual manner, but their full potential is often restrained due to a limitation in the effective context length. The FOT addresses this issue by employing a training process inspired by contrastive learning, which enhances the structure of the (key, value) space and enables an extension of the context length.
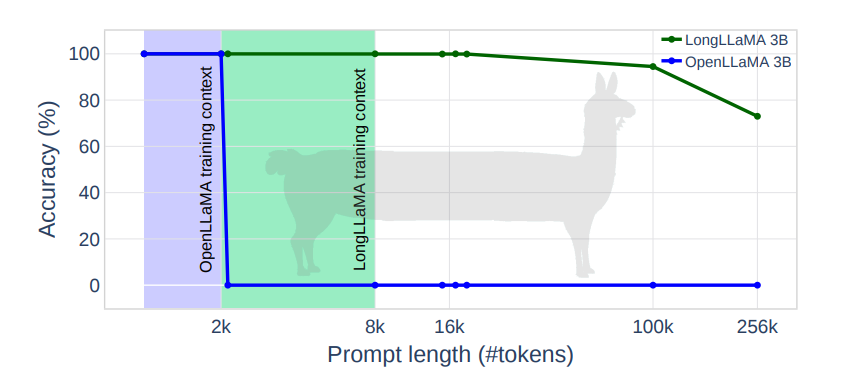
The FOT allows for the fine-tuning of pre-existing, large-scale models to lengthen their effective context. This is demonstrated by the fine-tuning of 3B and 7B OpenLLaMA checkpoints. The resulting models, named LONGLLAMA, exhibit advancements in tasks requiring a long context. They adeptly manage a 256k context length for passkey retrieval, showing significant improvements on tasks necessitating long-context modeling.
Publication date: July 6, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2307.03170.pdf