
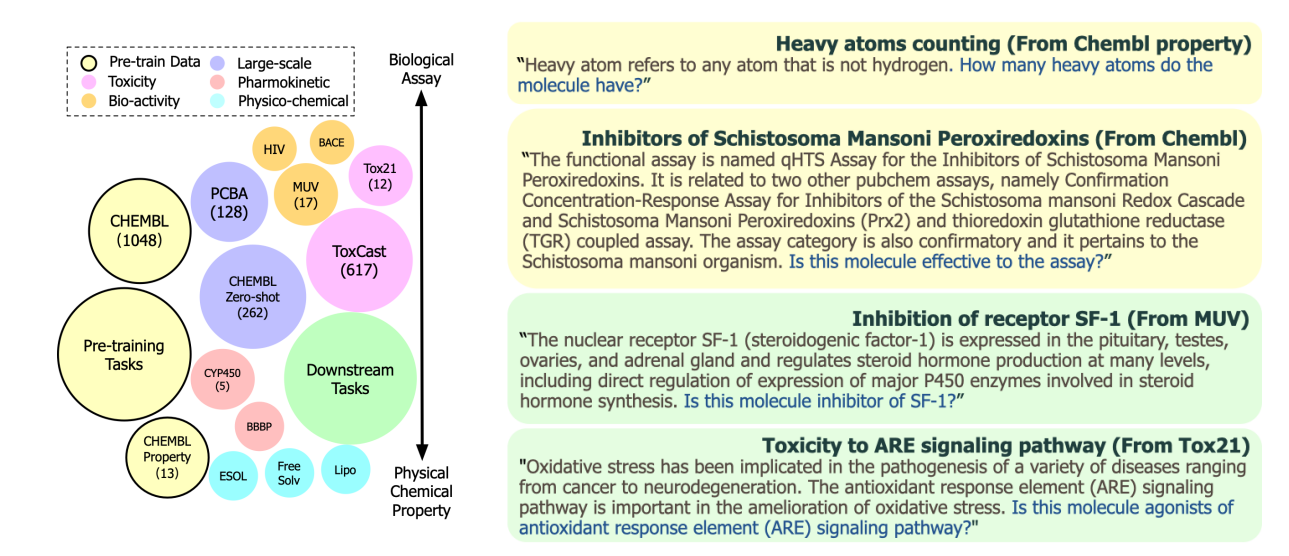
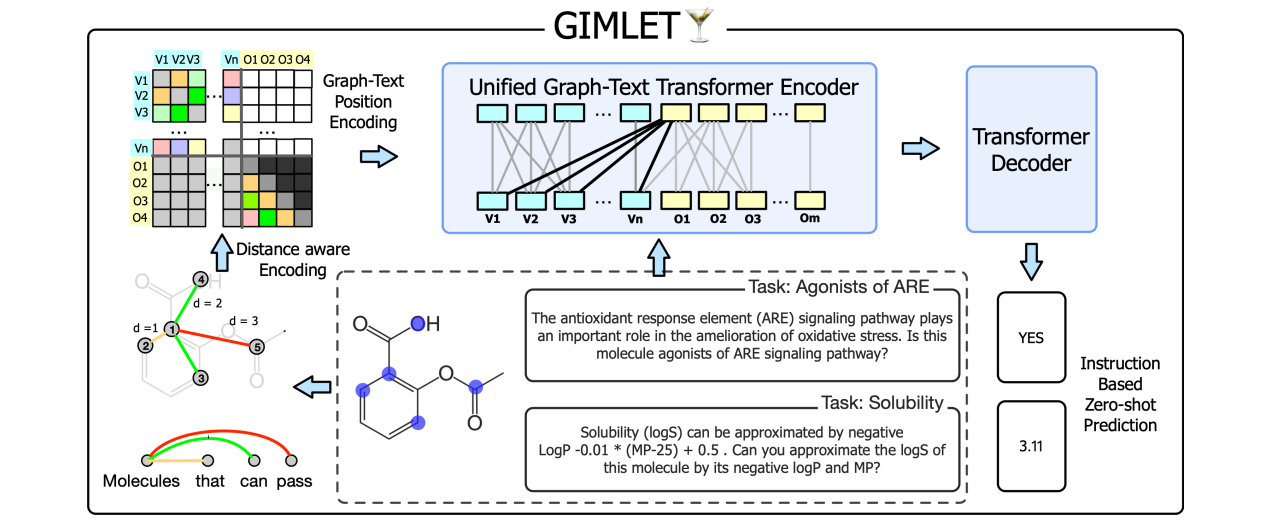
The paper introduces GIMLET, a unified graph-text model designed to address the challenges of molecule property prediction. The primary issue in this field is the lack of sufficient labels due to the high cost of lab experiments. GIMLET is developed to alleviate this problem by leveraging natural language instructions to perform molecule-related tasks in a zero-shot setting. The model unifies language models for both graph and text data, and it’s extended to encode both graph structures and instruction text without additional graph encoding modules. The model is pretrained on a dataset consisting of more than two thousand molecule tasks with corresponding instructions, enabling it to effectively transfer to a broad range of tasks. Experimental results show that GIMLET significantly outperforms molecule-text baselines in instruction-based zero-shot learning.
Publication date: May 28, 2023
Project Page: https://github.com/zhao-ht/GIMLET
Paper: https://arxiv.org/pdf/2306.13089.pdf