
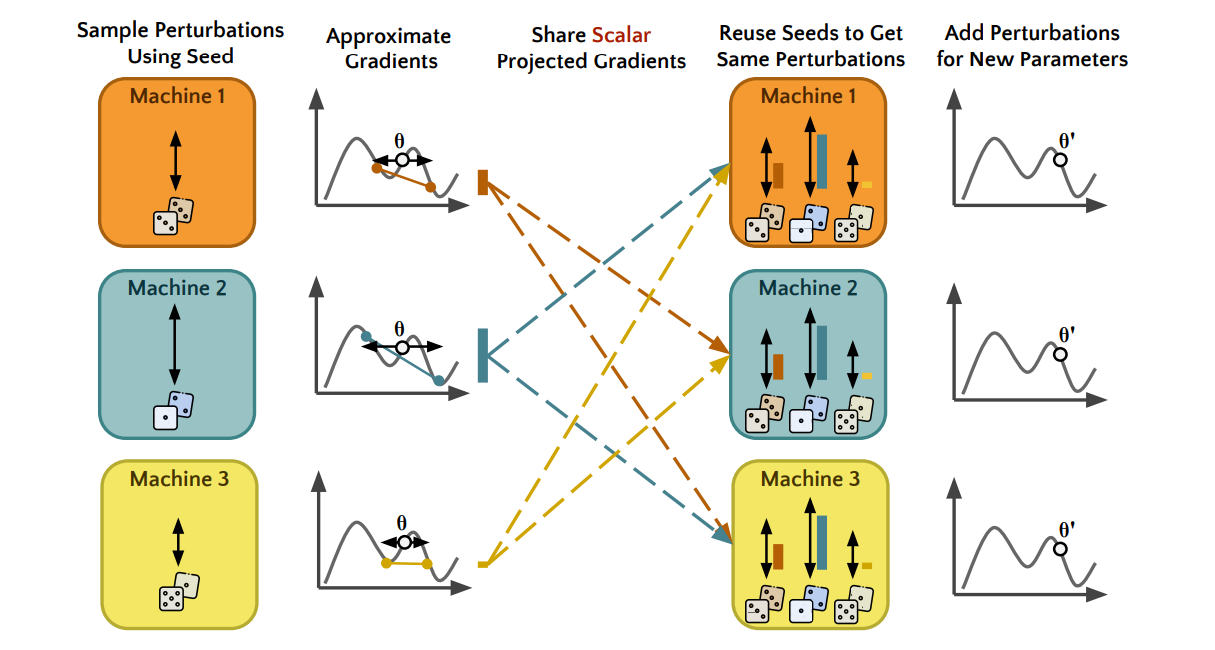
This paper presents a low-bandwidth, decentralized language model fine-tuning approach that leverages shared randomness. The method is an extension of the memory-efficient Simultaneous Perturbation Stochastic Approximation (SPSA) and uses shared randomness to perform distributed fine-tuning with low bandwidth. Each machine seeds a Random Number Generator (RNG) to perform local reproducible perturbations on model weights and calculate and exchange scalar projected gradients, which are then used to update each model. This technique reduces communication costs, offers potential privacy enhancement, and allows adding or removing machines during the training process.
Publication date: June 16, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2306.10015.pdf