

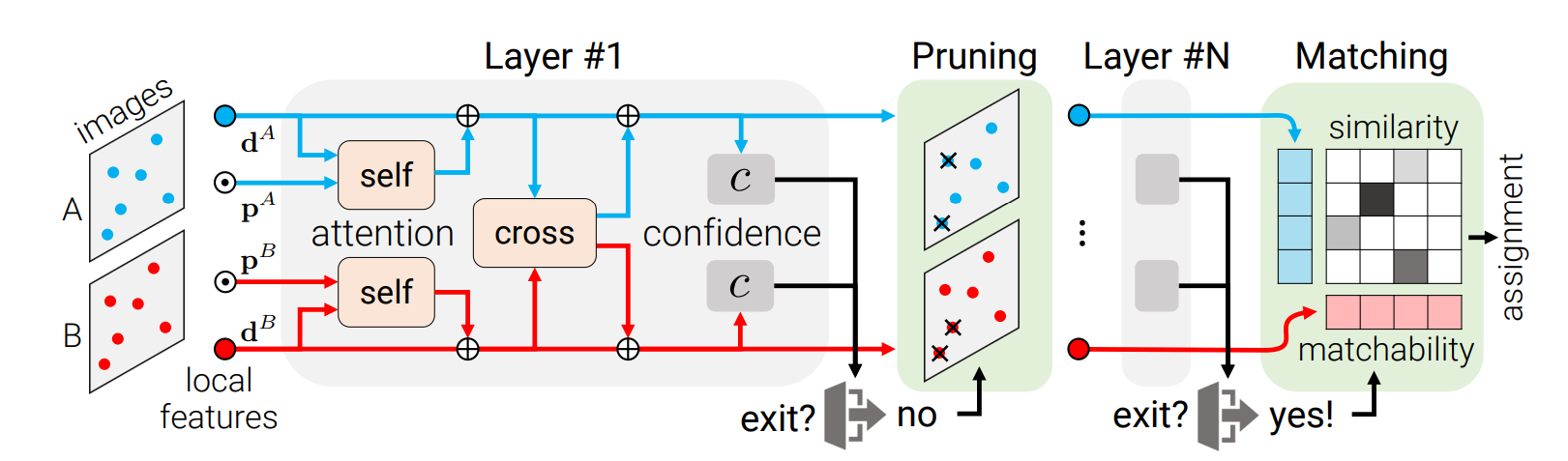
LightGlue is a deep learning model designed to match local features across images. It improves upon SuperGlue, the current state-of-the-art in sparse matching, by offering more efficient memory and computation usage, higher accuracy, and easier training. One of the key properties of LightGlue is its adaptability to the difficulty of the problem. This means that the inference is much faster on image pairs that are intuitively easier to match, for example, because of a larger visual overlap or limited appearance change. This adaptability opens up exciting prospects for deploying deep matchers in latency-sensitive applications like 3D reconstruction.
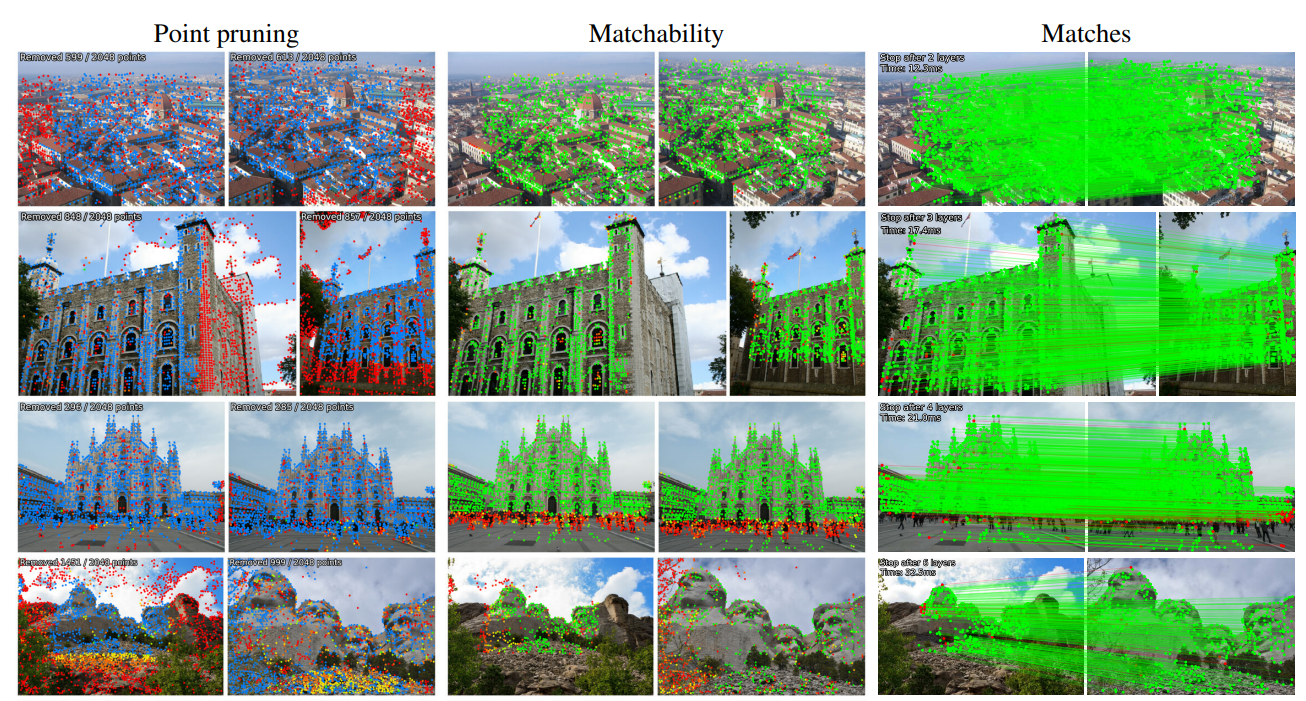
The LightGlue model is designed to be more accurate, more efficient, and easier to train than SuperGlue. It revisits the design decisions of SuperGlue and combines numerous simple, yet effective, architecture modifications. The model is adaptive to the difficulty of each image pair, which varies based on the amount of visual overlap, appearance changes, or discriminative information. This adaptability allows the model to process image pairs much faster when they are intuitively easier to match than challenging ones. This behavior is reminiscent of how humans process visual information. The LightGlue model and its training code are publicly available, opening up exciting prospects for deploying deep matchers in latency-sensitive applications like SLAM or reconstructing larger scenes from crowd-sourced data.
Publication date: June 23, 2023
Project Page: https://github.com/cvg/LightGlue
Paper: https://arxiv.org/pdf/2306.13643v1.pdf