
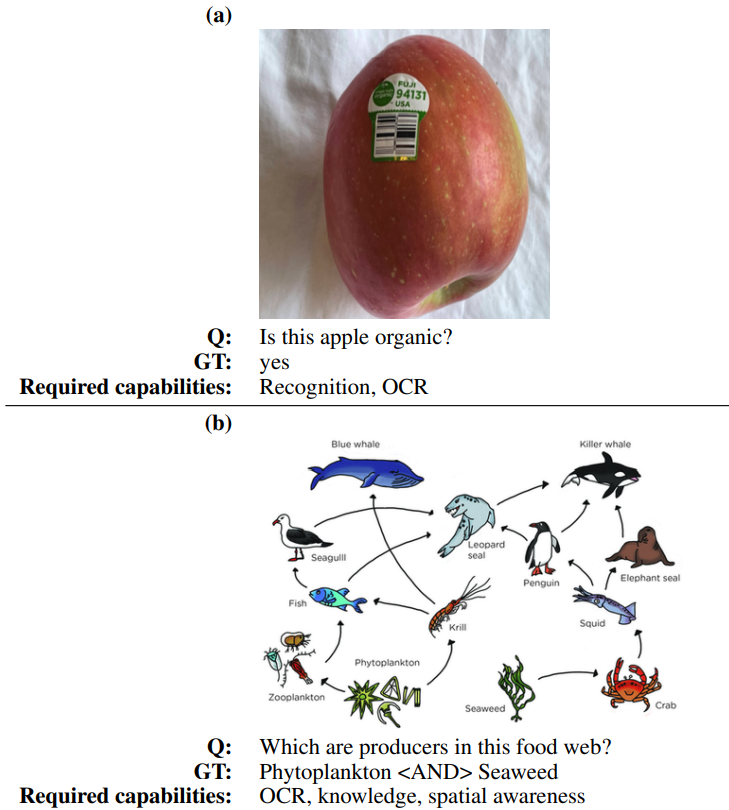
In the pursuit of mastering intricate multimodal tasks, the paper introduces MM-Vet, an evaluation benchmark tailored for Large Multimodal Models (LMMs). LMMs, which enhance large language models (LLMs) with multimodal inputs, have exhibited an impressive ability to tackle various challenging tasks, from understanding visual jokes to reasoning about current events. MM-Vet emphasizes the evaluation of these models based on their capability to merge core vision-language functionalities. The benchmark defines six foundational VL capabilities (recognition, OCR, knowledge, language generation, spatial awareness, and math) and assesses 16 integrations derived from these capabilities. This new method of evaluation aims to provide a systematic approach for quantifying the effectiveness and competence of LMMs in diverse scenarios.
Publication date: Aug 7, 2023
Project Page: https://github.com/yuweihao/MM-Vet
Paper: https://arxiv.org/pdf/2308.02490.pdf