
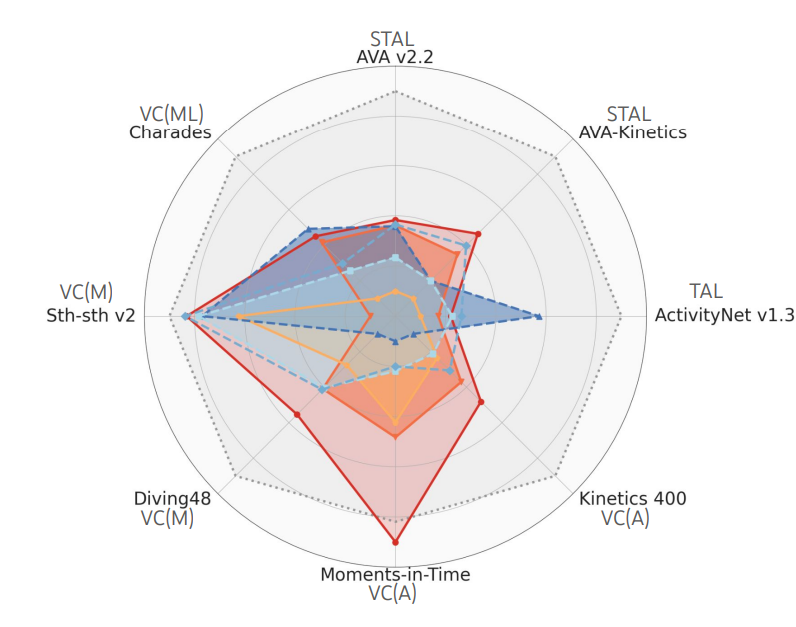
This research evaluates the video understanding capabilities of existing foundation models (FMs) using a specially designed experiment protocol, VideoGLUE. The study uses three key tasks (action recognition, temporal localization, and spatiotemporal localization), eight community-approved datasets, and four adaptation methods to tailor an FM for a downstream task. The paper also introduces a scalar VideoGLUE score (VGS) to measure an FM’s efficacy and efficiency when adapting to general video understanding tasks. The findings reveal the need for more research on video-focused FMs and confirm that both tasks and adaptation methods matter when evaluating FMs.
Publication date: July 6, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2307.03166.pdf