
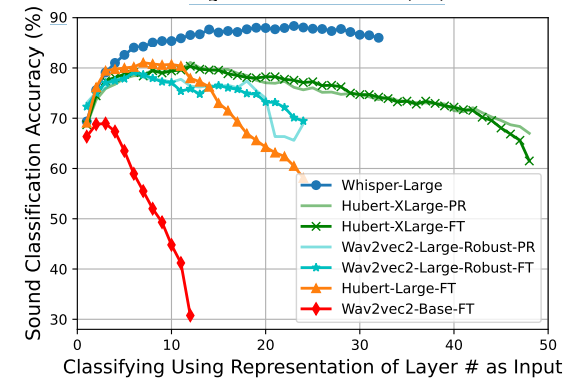
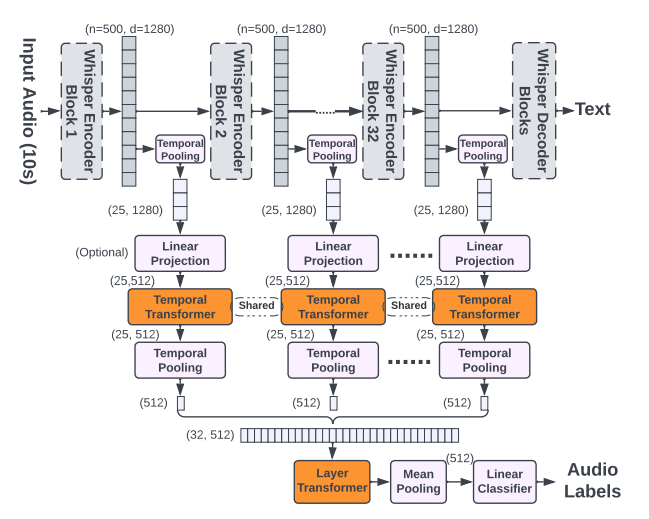
This paper focuses on Whisper, a recent automatic speech recognition model trained with a massive 680k hour labeled speech corpus recorded in diverse conditions. The authors show an interesting finding that while Whisper is very robust against real-world background sounds (e.g., music), its audio representation is not noise-invariant, but is instead highly correlated to non-speech sounds. This indicates that Whisper recognizes speech conditioned on the noise type. With this finding, the authors build a unified audio tagging and speech recognition model Whisper-AT by freezing the backbone of Whisper, and training a lightweight audio tagging model on top of it. With less than 1% extra computational cost, Whisper-AT can recognize audio events, in addition to spoken text, in a single forward pass.
Publication date: Jul 6, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2307.03183.pdf