



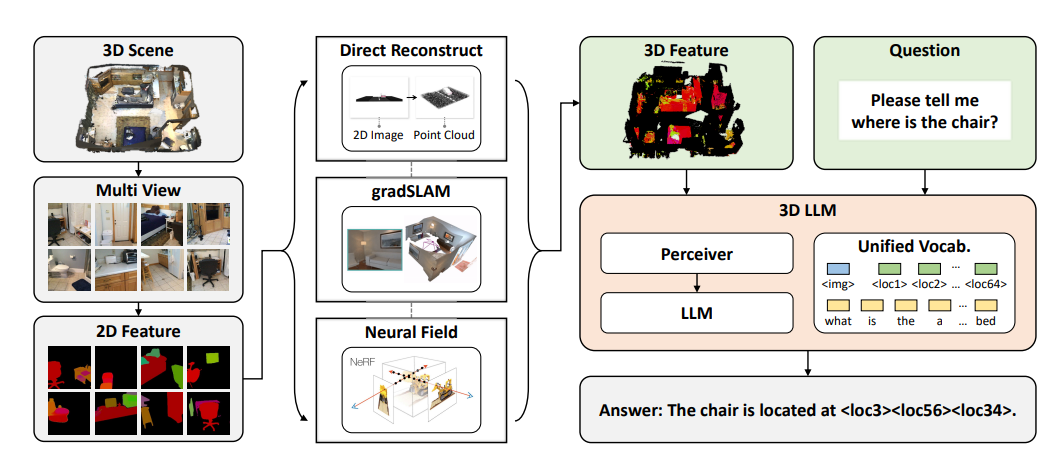

In this study, researchers propose a new class of language models known as 3D Large Language Models (3D-LLMs) that incorporate understanding of the 3D physical world. Current language models, despite their effectiveness in tasks such as commonsense reasoning, lack grounding in 3D concepts like spatial relationships, affordances, and physics. 3D-LLMs aim to fill this gap by taking 3D point clouds and their features as input, enhancing their capability to execute tasks related to the 3D environment, including 3D captioning, 3D question answering, navigation, and more.
To train these 3D-LLMs efficiently, the team first employed a 3D feature extractor that gets 3D features from rendered multi-view images, and then used 2D Vision-Language Models (VLMs) as their backbones to train the 3D-LLMs. Experiments on the ScanQA dataset showed the model outperforming existing baselines significantly, marking a promising step forward in the development of AI systems that can better comprehend and interact with the 3D physical world.
Publication date: 24 July 2023
Project Page: https://vis-www.cs.umass.edu/3dllm/
Paper: https://arxiv.org/pdf/2307.12981.pdf
