


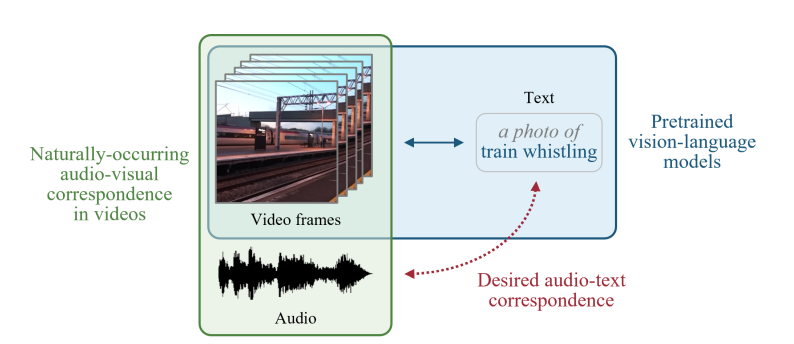
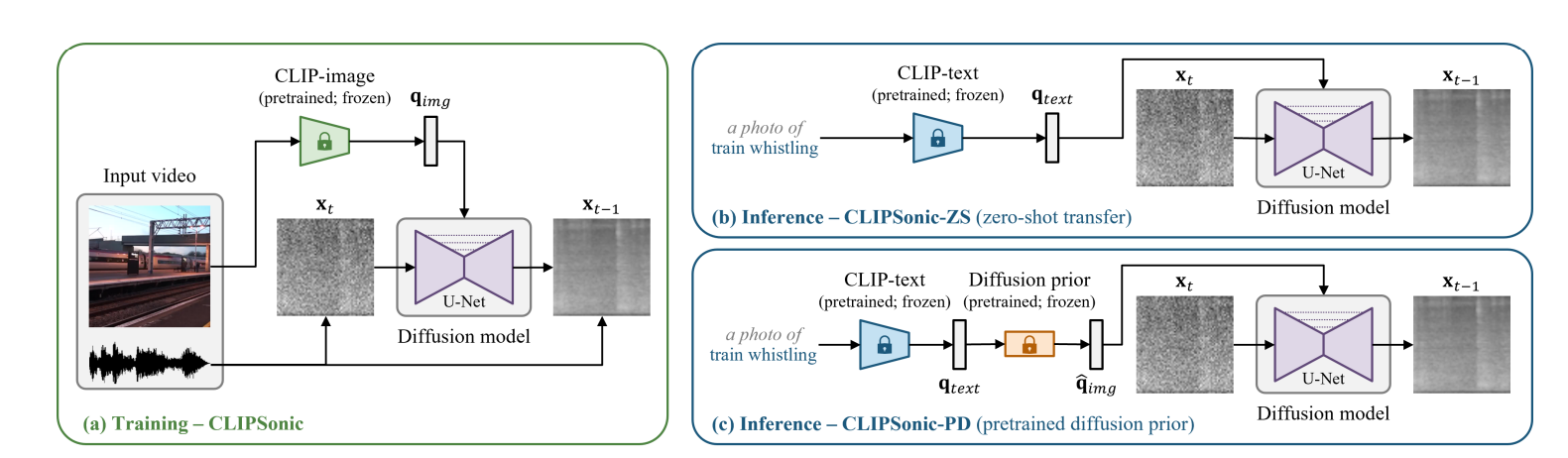

CLIPSONIC is a novel approach to text-to-audio synthesis that leverages unlabeled videos and pretrained language-vision models. The study aims to address the challenge of acquiring high-quality text annotations for audio recordings by using the visual modality as a bridge. The proposed method trains a conditional diffusion model to generate the audio track of a video, given a video frame encoded by a pretrained contrastive language-image pretraining (CLIP) model. The model shows competitive performance against a state-of-the-art image-to-audio synthesis model in a subjective listening test. This study offers a new direction of approaching text-to-audio synthesis that leverages the naturally-occurring audio-visual correspondence in videos and the power of pretrained language-vision models.
Publication date: June 16, 2023
Project Page: N/A
Paper: https://salu133445.github.io/clipsonic/
