


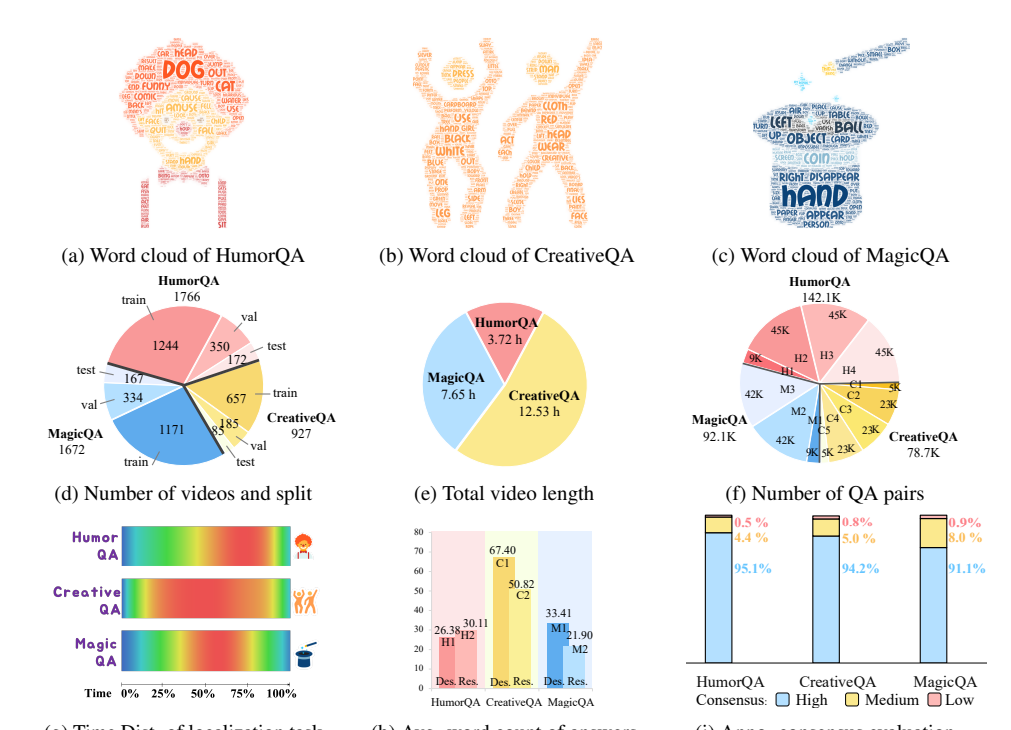
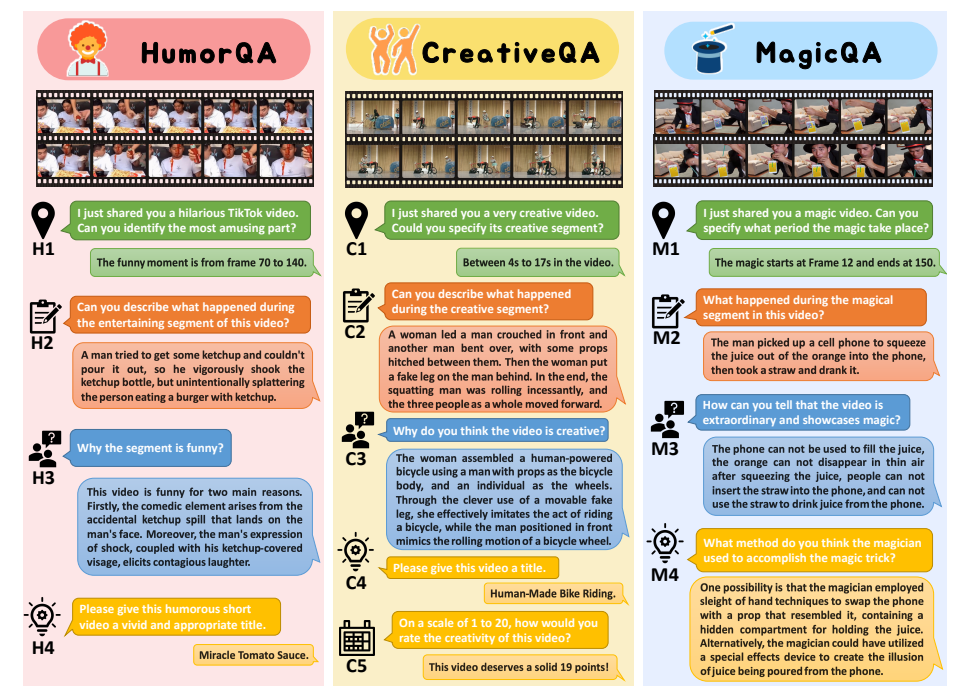

FunQA is a novel dataset that aims to push the boundaries of video comprehension by focusing on surprising and fun videos. The dataset is divided into three subsets: HumorQA, CreativeQA, and MagicQA, each offering a unique set of challenges. The goal is to evaluate and enhance the depth of video reasoning, focusing on counter-intuitive and fun elements in videos.
The dataset introduces rigorous QA tasks designed to assess a model’s capability in counter-intuitive timestamp localization, detailed video description, and reasoning around counter-intuitiveness. Additionally, higher-level tasks are posed, such as attributing a fitting and vivid title to the video and scoring the video’s creativity. This approach pushes video reasoning beyond superficial descriptions, demanding a deeper understanding and discernment.
Publication date: June 27, 2023
Project Page: https://github.com/Jingkang50/FunQA
Paper: https://arxiv.org/pdf/2306.14899.pdf
