
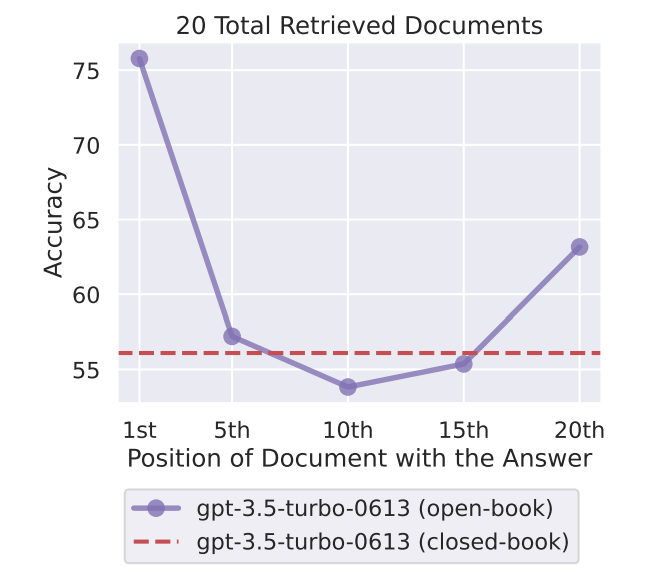
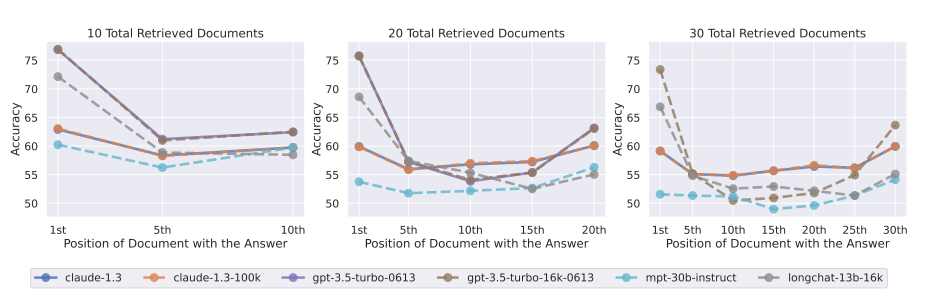
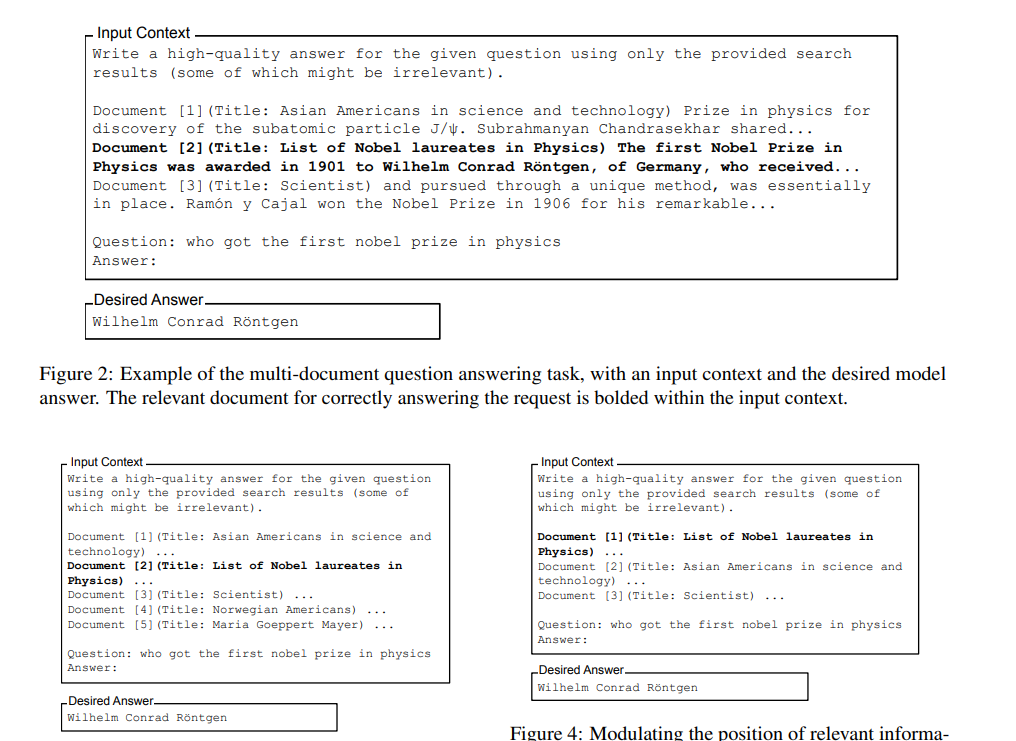
The study “Lost in the Middle: How Language Models Use Long Contexts” investigates how language models utilize long contexts. The researchers found that these models perform best when the relevant information is at the beginning or end of the input context. However, when the models need to access relevant information in the middle of long contexts, their performance significantly degrades. This performance drop is observed even in models that are explicitly designed to handle long-context tasks.
The study also reveals that as the input context grows longer, the performance of the models decreases substantially. This finding is critical as it suggests that simply increasing the context length does not necessarily improve the model’s ability to use the input context effectively. The research provides valuable insights for the development of future long-context models and contributes to a better understanding of how language models use their input context.
Publication date: July 6, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2307.03172.pdf