


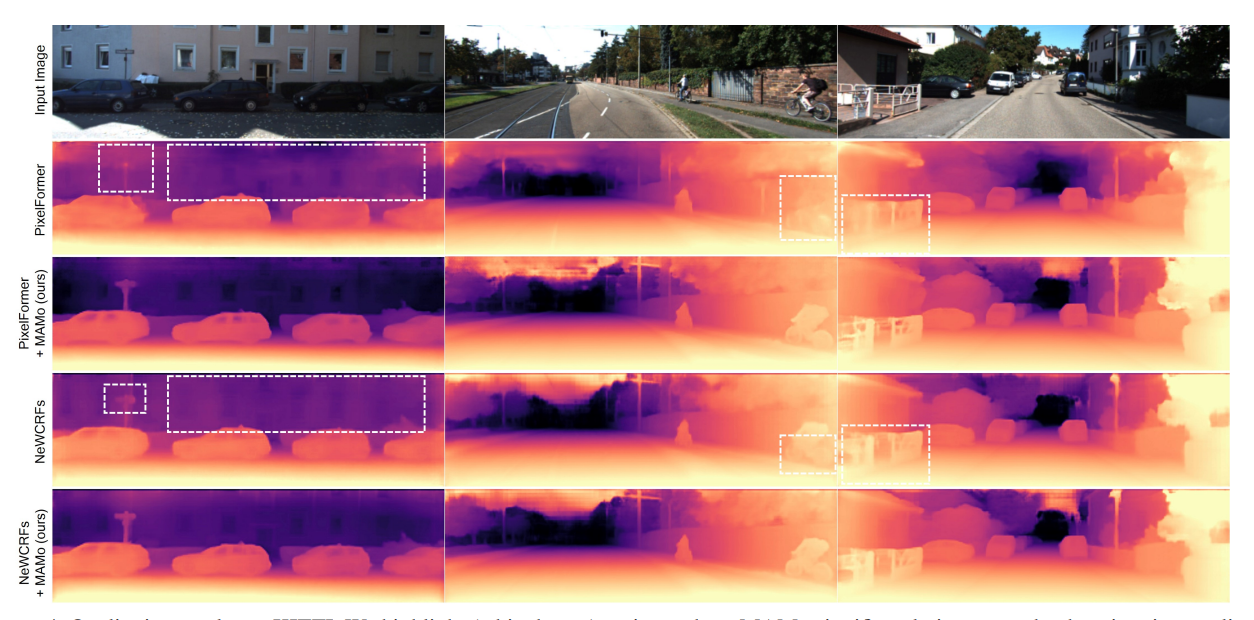
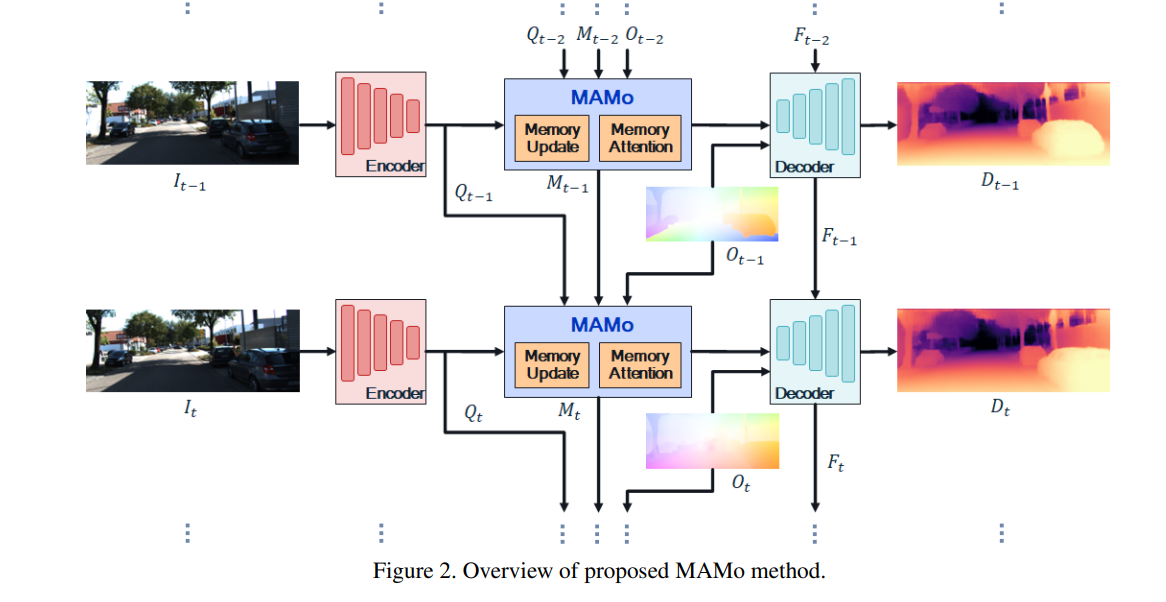

In this research, the authors introduce a novel framework, MAMo, designed to enhance the accuracy of video depth estimation from monocular data. By incorporating memory and attention mechanisms, MAMo enables any single-image depth estimation model to consider temporal information for more accurate depth predictions. It is optimized to store tokens corresponding to past and present visual data, improving the model’s depth predictions as it processes a video. The use of an attention-based approach ensures optimal processing of memory features. Through rigorous experiments, the MAMo model has demonstrated consistent improvements in monocular depth estimation networks, establishing new standards for accuracy.
Publication date: 26 July 2023
Project Page: Not provided
Paper: https://arxiv.org/pdf/2307.14336.pdf
