


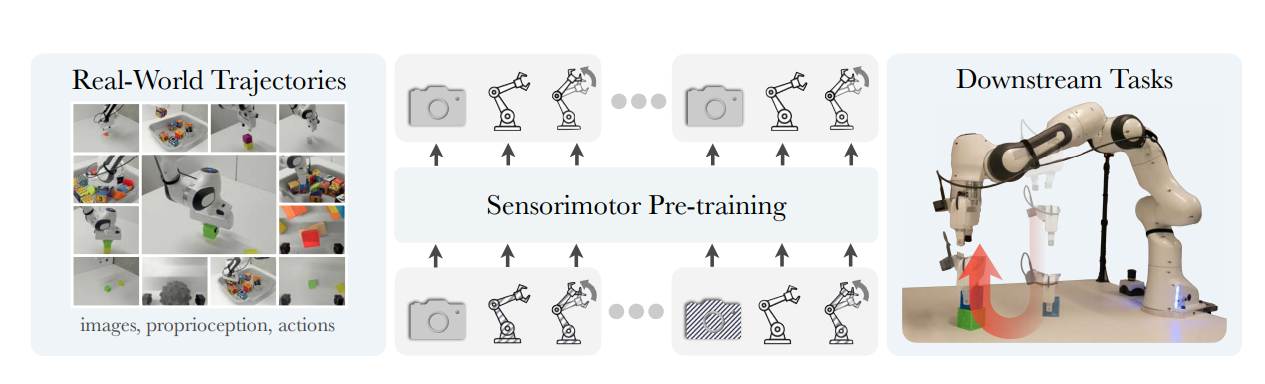
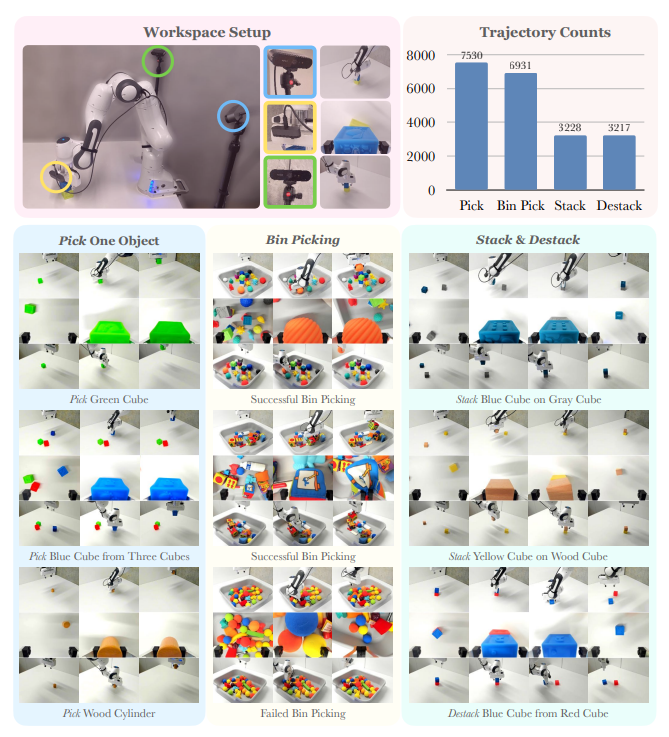

This paper presents a self-supervised sensorimotor pre-training approach for robotics. The authors propose a model, called RPT (Robot Pre-training Transformer), that operates on sequences of sensorimotor tokens. The model is trained to predict masked-out content from a sequence of camera images, proprioceptive robot states, and past actions. The authors hypothesize that if the robot can predict the missing content, it has acquired a good model of the physical world that can enable it to act. The RPT model is designed to operate on latent visual representations, which makes prediction tractable, enables scaling to larger models, and facilitates real-time inference on a physical robot. The authors evaluate their approach using a dataset of 20,000 real-world trajectories collected over 9 months and find that pre-training consistently outperforms training from scratch, leading to significant improvements in tasks like block stacking.

Publication date: June 16, 2023
Project Page: https://robotic-pretrained-transformer.github.io/
Paper: https://arxiv.org/pdf/2306.10007.pdf
