


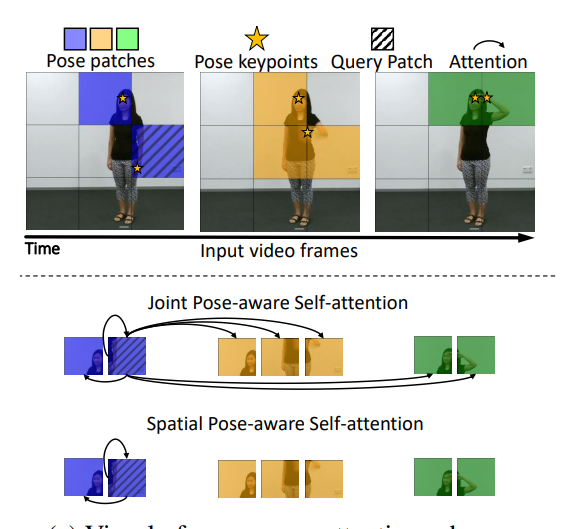
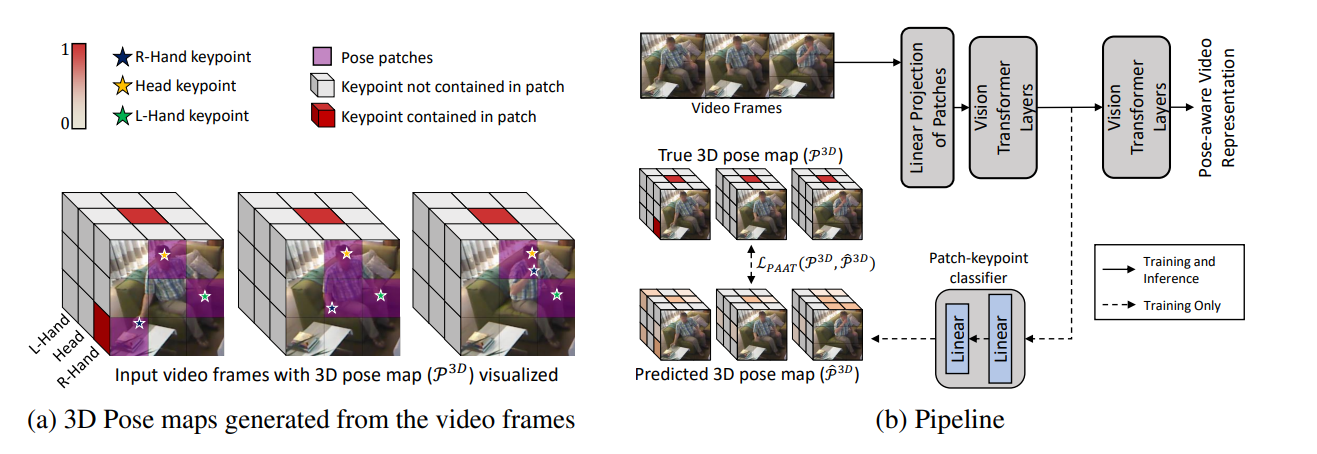

The paper presents two strategies for learning pose-aware representations in Vision Transformers (ViTs). The first strategy, called Pose-aware Attention Block (PAAB), is a plug-and-play ViT block that performs localized attention on pose regions within videos. The second strategy, dubbed Pose-Aware Auxiliary Task (PAAT), presents an auxiliary pose prediction task optimized jointly with the primary ViT task. Both methods enhance performance in multiple diverse downstream tasks, surpassing their respective backbone Transformers by up to 9.8% in real-world action recognition and 21.8% in multi-view robotic video alignment.
The authors argue that human perception of surroundings is often guided by various poses present within the environment. Many computer vision tasks, such as human action recognition and robot imitation learning, rely on pose-based entities like human skeletons or robotic arms. However, conventional Vision Transformer (ViT) models uniformly process all patches, neglecting valuable pose priors in input videos. The authors believe that incorporating poses into RGB data is advantageous for learning fine-grained and viewpoint-agnostic representations. The paper’s experiments, conducted across seven datasets, reveal the efficacy of both pose-aware methods on three video analysis tasks, with PAAT holding a slight edge over PAAB.
Publication date: June 15, 2023
Project Page: https://github.com/dominickrei/PoseAwareVT
Paper: https://arxiv.org/pdf/2306.09331.pdf
