


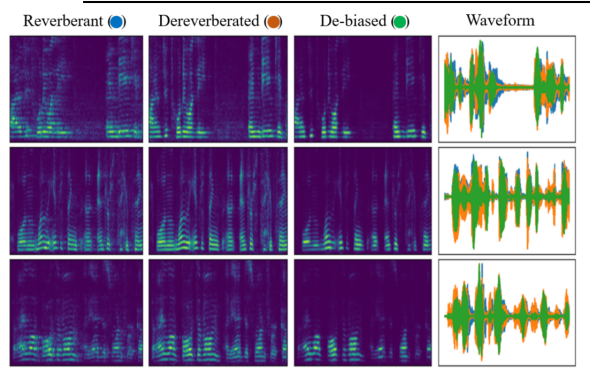
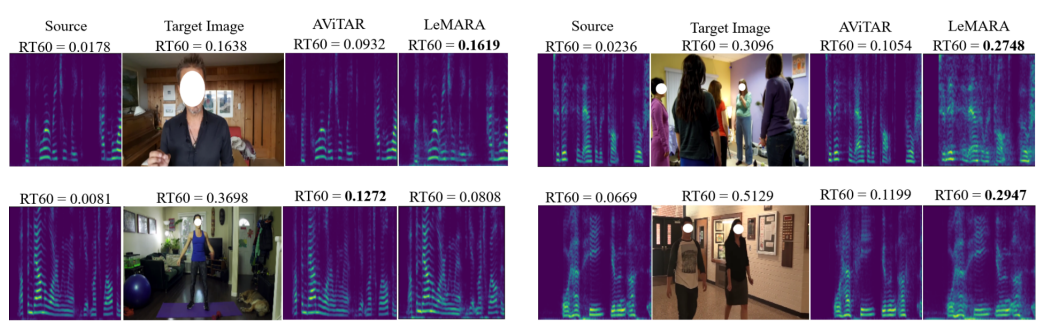

The study introduces a self-supervised approach to visual acoustic matching, aiming to improve the experience of audio perception in diverse spaces. By learning to disentangle room acoustics and re-synthesize audio into the target environment, the new model overcomes limitations of existing methods that demand paired training data, thus making it usable for larger scale and diverse environments.
Publication date: 27 July 2023
Project Page: Not provided
Paper: https://arxiv.org/pdf/2307.15064.pdf
Leave a comment
