

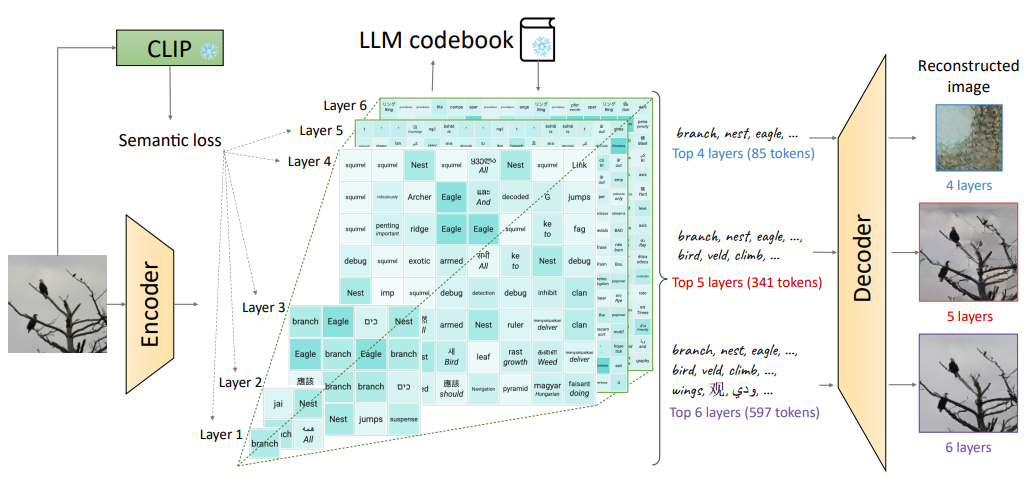
The Semantic Pyramid AutoEncoder (SPAE) is a groundbreaking tool that allows frozen Large Language Models (LLMs) to perform tasks involving non-linguistic modalities, such as images or videos. It does this by converting raw pixels into interpretable lexical tokens, which are extracted from the LLM’s vocabulary. These tokens capture both the semantic meaning and the fine-grained details necessary for visual reconstruction, effectively translating visual content into a language that the LLM can understand. This allows the LLM to perform a wide range of multimodal tasks. The method has been validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. This method represents the first successful attempt to enable a frozen LLM to generate image content, surpassing state-of-the-art performance in image understanding tasks by over 25% under the same conditions.
Publication date: July 3, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2306.17842.pdf