
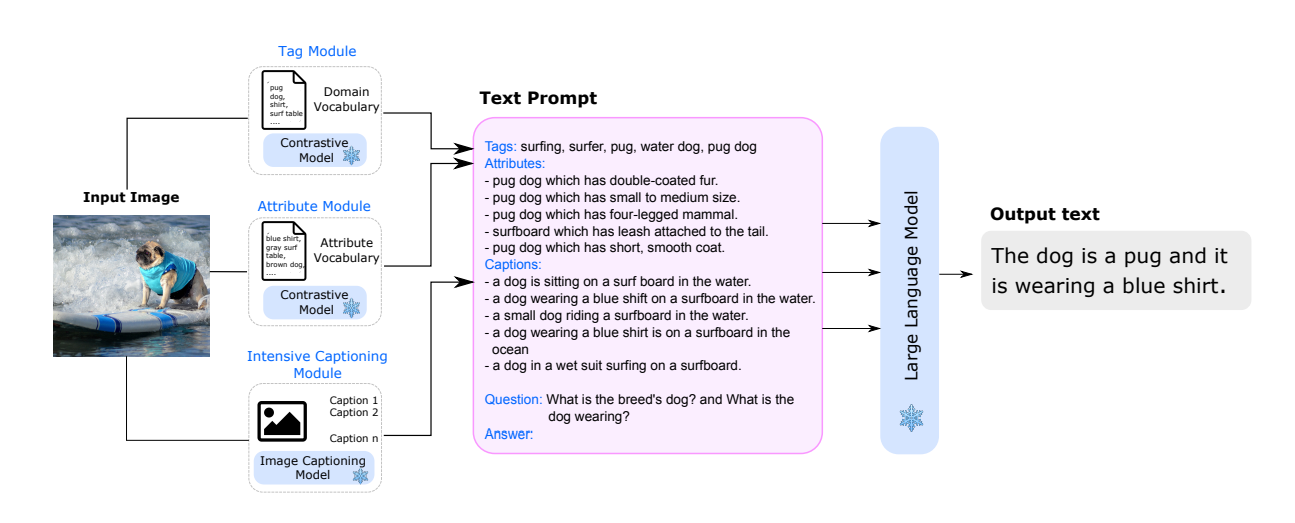
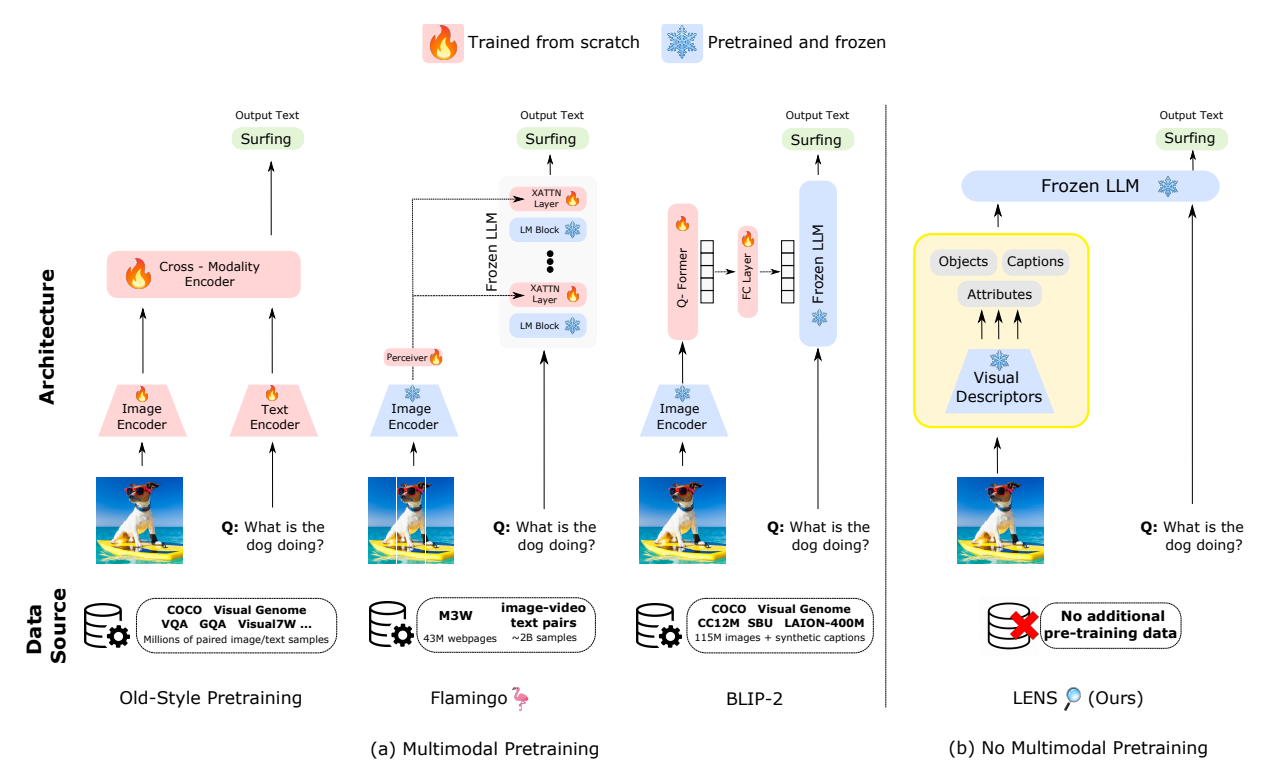
LENS (Large Language Models ENhanced to See) is a novel system that leverages the power of large language models (LLMs) to tackle computer vision problems. The system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. This approach is evaluated in pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and performs competitively with much bigger and more sophisticated systems, without any multimodal training.
The LENS approach first extracts rich textual information using pretrained vision modules such as contrastive models and image-captioning models. Subsequently, the text is fed into the LLM allowing it to perform object recognition and vision and language (V&L) tasks. LENS eliminates the need for extra multimodal pretraining stages or data, bridging the gap between the modalities at zero cost. By integrating LENS, we get a model which works across domains out of the box without any additional cross-domain pretraining. This integration enables us to leverage the latest advancements in both computer vision and natural language processing out of the box, maximizing the benefits derived from these fields.
Publication date: June 28, 2023
Project Page: https://lens.contextual.ai/
Paper: https://arxiv.org/pdf/2306.16410.pdf