


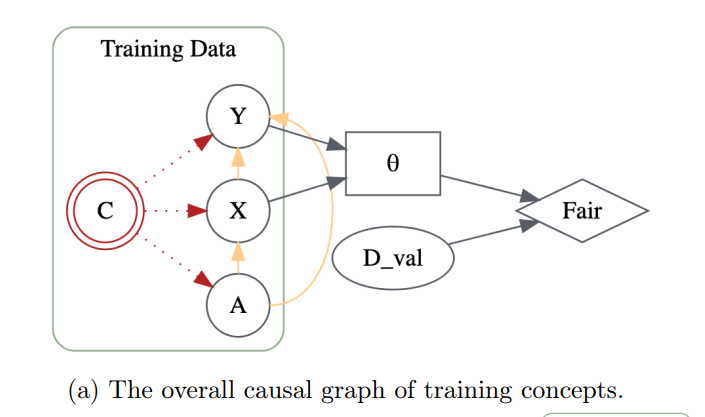
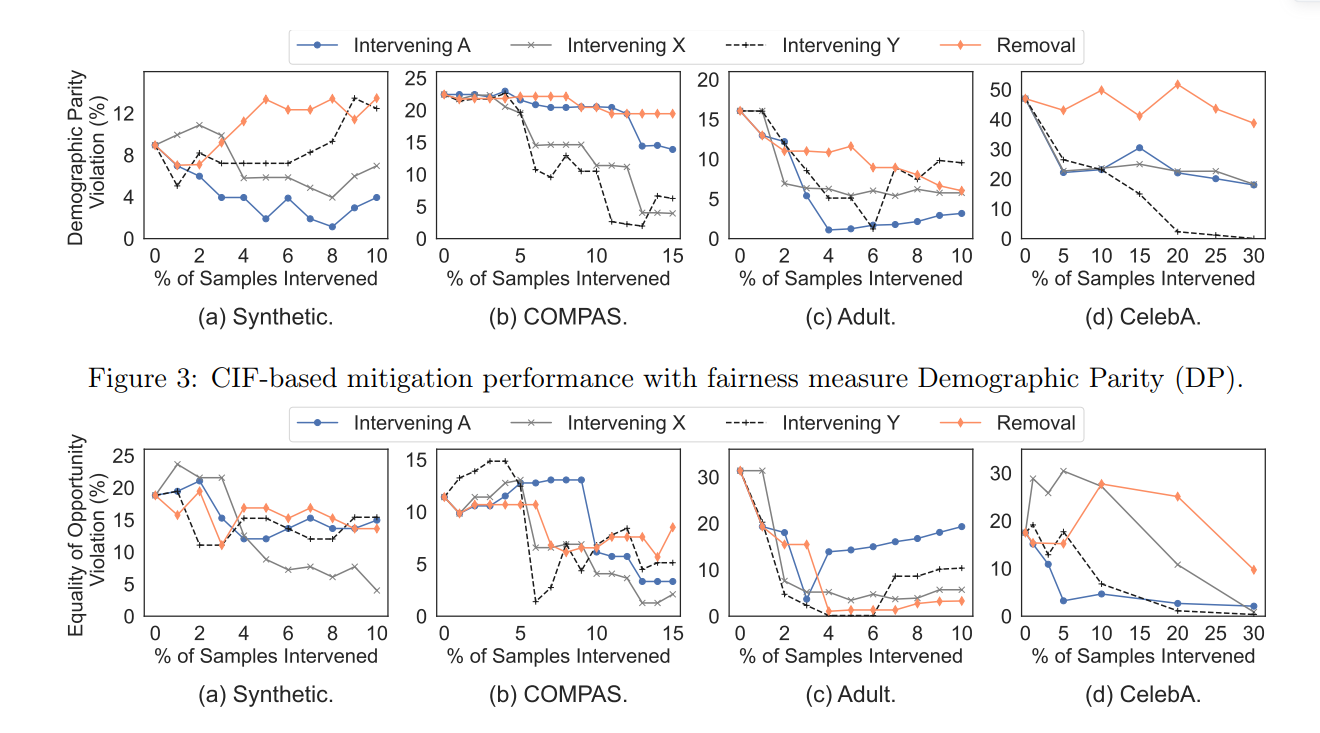

This paper presents a novel framework, Concept Influence for Fairness (CIF), to understand and address the issue of unfairness in machine learning models. The authors propose a method to quantify the influence of training data samples on the fairness of a model. By counterfactually intervening and changing samples based on predefined concepts, such as features, labels, or sensitive attributes, they assess the impact of these changes on the model’s fairness. This approach not only helps practitioners understand and rectify the observed unfairness in their training data, but also leads to various other applications, such as detecting mislabeling, fixing imbalanced representations, and identifying fairness-targeted poisoning attacks.
Publication date: June 30, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2306.17828.pdf
