


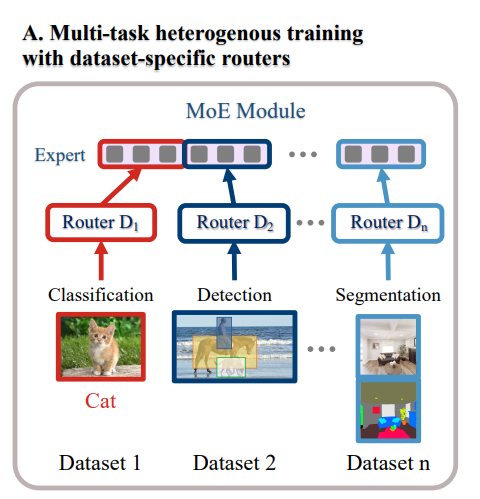
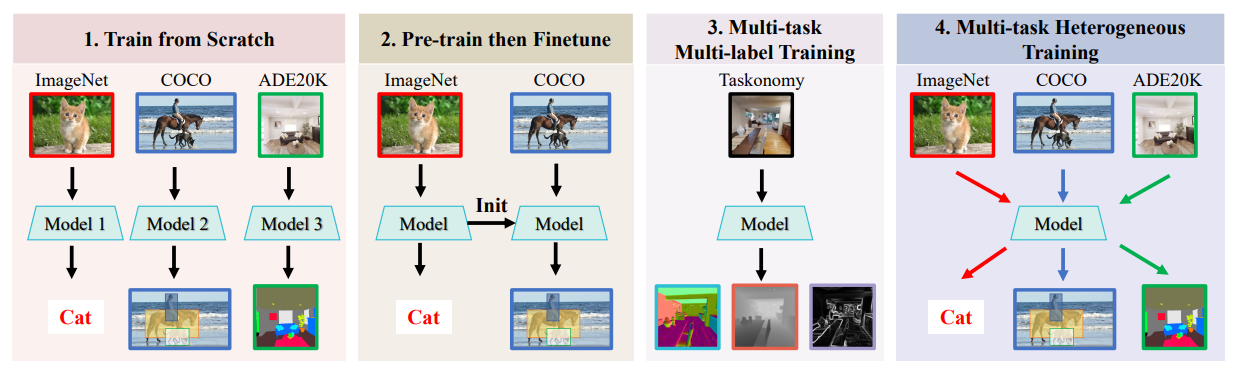

The model presented in this paper is designed to address the challenges of multi-task learning in the field of computer vision. It is built upon a mixture-of-experts (MoE) vision transformer and is trained on diverse mainstream vision datasets. The model is capable of performing multiple vision tasks such as classification, detection, and segmentation. It demonstrates strong generalization on downstream tasks and can be fine-tuned with fewer training parameters, fewer model parameters, and less computation. The model’s modularity allows for easy expansion in continual-learning-without-forgetting scenarios. This makes the model highly adaptable and efficient for various vision tasks.
Publication date: June 29, 2023
Project Page: N/A
Paper: https://arxiv.org/pdf/2306.17165.pdf
