


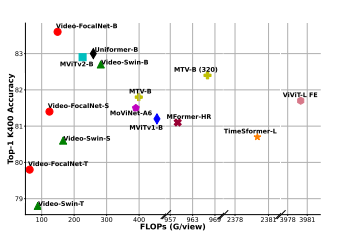
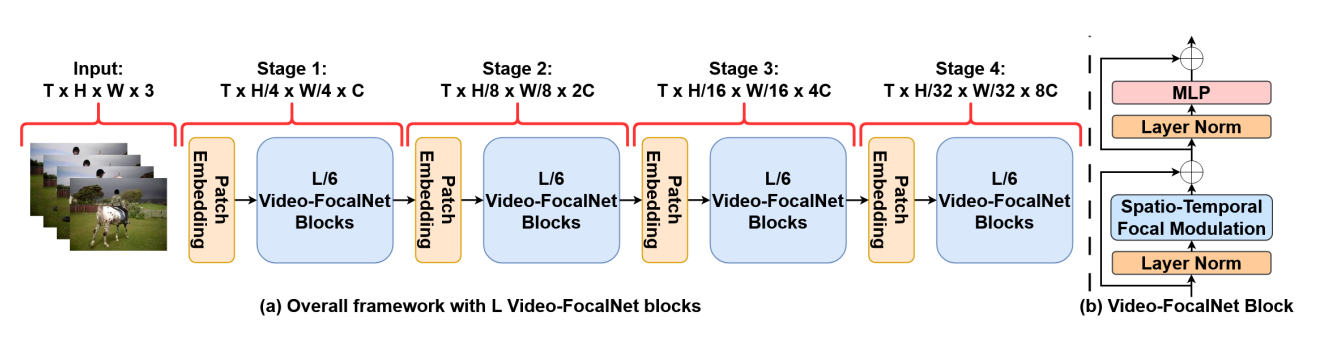

In the field of video recognition, achieving high performance usually entails significant computational costs. The proposed Video-FocalNets effectively merges the efficiency of convolutional designs with the global context modeling of transformers. While convolutional designs are excellent for short-range modeling and are computationally efficient, they struggle with long-range dependencies. On the other hand, transformers (specifically, Vision Transformers or ViTs) offer long-range context modeling but at the expense of high computational cost. The introduced Video-FocalNets leverages a spatio-temporal focal modulation architecture that seeks to balance these trade-offs.
The key innovation of Video-FocalNets lies in reversing the steps of the self-attention operation, a prevalent technique in transformer designs, for improved efficiency. This new model uses more cost-effective operations like convolution and element-wise multiplication, which are less computationally demanding compared to the self-attention counterparts. The approach shows promise in achieving an optimal balance of computational cost and performance, outperforming similar models in key video recognition benchmarks while consuming less computational resources.
Publication date: July 13, 2023
Project Page: Not available
Paper: https://arxiv.org/abs/2307.06947
